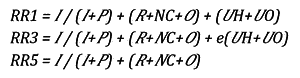Después de rellenar el informe del usuario, disponible aquí, todo usuario con afiliación científica puede descargar los datos de forma gratuita, siempre que se utilice con fines estrictamente científicos. Para más información sobre los términos y condiciones de acceso a la base de datos, pinche aquí.
1.2 ¿Dónde puede descargarse la base de datos?
La base de datos SHARE está distribuida por CenterData, ubicada en el campus de la universidad de Tilburg en Holanda. El proceso de descarga y las condiciones para acceder a la base de datos se describen aquí.
1.3 ¿Qué formatos de datos están disponibles?
La base de datos SHARE está disponible en formatos válidos para Stata y SPSS. EasySHARE también está disponible para el software R. En caso de querer utilizar otro software estadístico, los datos deben ser transferidos por los mismos usuarios.
1.4 ¿Qué puedo hacer si olvido el nombre de usuario y/o la contraseña para descargar la base de datos?
Si olvida el nombre de usuario y/o la contraseña para acceder a la base de datos, por favor introduzca su correo electrónico aquí y recibirá un email recordándole su contraseña. Si no recuerda la dirección de email con la que se registró, por favor contacte con el centro de análisis de datos de SHARE.
2. DOCUMENTACIÓN
2.1 ¿Qué tipos de archivos existen?
Para facilitar el uso de los datos SHARE, se ofrecen una serie de documentos. El perfil de recursos 7.0.0 de la base de datos publicado en la Revista Internacional de Epidemiología, proporciona una visión general compacta de SHARE. Además de los cuestionarios longitudinales correspondientes a cada ola y los específicos de cada país, la guía de publicación de la ola 7 se dirige específicamente a aquellos usuarios interesados en trabajar con la base de datos.
2.2 ¿Qué tipos de cuestionarios se utilizan en SHARE?
SHARE se basa en el concepto de unificación ex-ante: hay un cuestionario general común traducido a los 40 idiomas nacionales (en algunos países se habla más de un idioma) utilizando un sistema de traducción online y procesándolo automáticamente en un instrumento CAPI (entrevista personal asistida por ordenador) común. Las versiones del cuestionario general y el específico de cada país pueden descargarse en la web de SHARE. Sin embargo, algunas variables internacionales muy diversas necesitan medidas específicas en cada país y una unificación posterior, como ocurre en el campo educativo (ISCED) o del empleo (ISCO, NACE).
Además de los cuestionarios generales y específicos, hay otros tipos especiales, como el de información general, auto cuestionarios, viñetas de ajuste o de salida. El cuestionario de información general es la primera parte de cada entrevista. Recolecta información demográfica básica sobre cada individuo viviendo en el hogar y es respondido únicamente por uno de ellos en representación del resto. La entrevista suele terminar con un auto cuestionario (ver pregunta 4.6). Otro tipo de auto cuestionario es el de viñetas de ajuste (ver pregunta 4.7) realizado en las olas 1 y 2. Estas viñetas de ajuste pretendían mejorar la comparabilidad entre países. Si algún entrevistado fallece entre dos olas, SHARE intenta realizar una entrevista de salida (ver pregunta 4.9) a un entrevistado interpuesto. El cuestionario de salida contiene principalmente información sobre las circunstancias de vida durante el último año de vida del entrevistado y la causa de su muerte.
3. METODOLOGÍA
3.1 ¿Cómo se recolectan los datos?
La recolección de datos se basa en una entrevista personal asistida por ordenador (CAPI). Los entrevistados realizan entrevistas cara a cara utilizando un ordenador portátil en el que se haya instalado CAPI. Las entrevistas personales son necesarias, ya que se realizan exámenes físicos y se recogen posibles marcadores biológicos. Las excepciones son los auto cuestionarios y las viñetas de ajuste que se responden a mano, así como el cuestionario de salida, realizado vía entrevista telefónica asistida por ordenador (CATI). Para más detalles sobre la recopilación de datos, puede visitar el siguiente enlace (versión en inglés).
3.2 ¿Quién es apto para realizar la entrevista?
SHARE se centra en población mayor de 50 años y en recoger en ella una muestra de aquellos que tienen su domicilio regular en el país de SHARE correspondiente. Las personas encarceladas, hospitalizadas o que se encuentran fuera del país durante todo el período en que se realiza la encuesta pueden ser excluidas del proceso, así como aquellas que no hablen el lenguaje oficial o que se hayan mudado a una dirección desconocida. En la primera ola, todas las personas nacidas en 1954 o antes fueron susceptibles de ser elegidas. Desde la segunda ola, para nuevos países o muestras de refresco, solo tiene que haber un individuo en el domicilio nacido en 1956 o antes para la ola 2, en 1960 o antes para la ola 4, en 1962 o antes para la ola 5, en 1964 o antes para la ola 6, y en 1966 o antes para la ola 7. Además, en todas las olas, las parejas que vivan en el domicilio serán entrevistadas independientemente de su edad.
Todos los encuestados que fueron entrevistados en olas anteriores forman parte de la muestra longitudinal. Si tienen una nueva pareja que conviva en el domicilio, esta también puede ser elegida para realizar una entrevista, independientemente de la edad. Los encuestados serán sometidos a un seguimiento para volver a ser entrevistados en caso de mudarse a otro país o para realizar una entrevista de defunción o salida en caso de fallecer. Las parejas que sean más jóvenes, las nuevas parejas o aquellas que nunca hayan participado en una entrevista SHARE no serán sometidas a seguimiento ni se les realizará una entrevista de salida.
3.3 ¿Por qué hay diferentes tipos de encuestados?
Para ahorrar tiempo y reducir la carga de las entrevistas, la entrevista CAPI principal está diseñada de forma que no todos los entrevistados de una misma unidad familiar respondan todos los módulos de la encuesta. Los entrevistados de una unidad familiar responden preguntas sobre la vivienda, los ingresos familiares y el consumo representativo de todos los miembros de la familia. En nombre de la pareja, quien responde a la encuesta financiera contesta preguntas sobre transferencias financieras y activos, y quien responde a la encuesta familiar contesta preguntas sobre los hijos y las ayudas sociales (también en nombre de la pareja). Los tipos de entrevistados se especifican en las variables hou_resp (si representa los aspectos del hogar), fin_resp (si representa el carácter financiero) y fam_resp (si representa a la familia) en el módulo cv_r, así como en el de variables técnicas. El cuestionario SHARELIFE no diferencia entre los tipos de encuestados.
3.4 ¿Qué son entrevistas representadas?
En caso de existir limitaciones físicas y/o cognitivas que dificulten a un encuestado completar una entrevista él mismo, existe la posibilidad de que este sea asistido por un representante para completarla (entrevistas “parcialmente representadas”. Si el representante responde toda la encuesta en lugar del encuestado al que corresponde, se tratará de una entrevista completamente representada. Ejemplos de condiciones bajo las cuales se permite realizar una entrevista representada son la pérdida de audición, problemas en el habla, Alzheimer y dificultades en concentrarse a lo largo de la entrevista. También se puede pedir a los representantes que realicen cuestionarios de salida en caso de fallecimiento del representado. Algunos módulos en los cuestionarios se definen como “secciones fuera de representación” porque estas no pueden ser respondidas por otras personas. El funcionamiento cognitivo, la salud mental (parcialmente), la fuerza de agarre, la velocidad al caminar, actividades y módulos de expectativas son secciones que no permiten representación. Otras secciones contienen la información sobre quién responde las preguntas de una sección al final del cuestionario longitudinal: (1) el encuestado, (2) el encuestado y su representante o (3) solo su representante.
3.5 ¿Cómo se calculan en SHARE las tasas de respuesta?
Dependiendo del marco de muestreo disponible, algunos países pueden necesitar un procedimiento de evaluación para determinar el estado de elegibilidad de los encuestados mientras que otros no necesitan una evaluación inicial. Basándose en esta diferenciación, hay diversas formas de calcular las tasas de respuesta finales, dependiendo en cómo sean manejados los casos de elegibilidad desconocida (ver la guía AAPOR para más información, versión en inglés):
I: número de entrevistas realizadas
P: número de entrevistas parciales
R: número de rechazos y desprendimientos.
NC: número de no contactados
O: número de entrevistas no realizadas por otra causa
UH: número de entrevistas con elegibilidad desconocida (desconocida si existe una unidad familiar)
UO: número de entrevistas con elegibilidad desconocida (por otra causa)
e: fracción de unidades elegibles entre los casos de conocida elegibilidad.
Para más información sobre los cálculos y las tasas de respuesta finales de SHARE a nivel de unidad familiar e individual por ola, país y ciertos subgrupos, visite este Documento técnico (inglés).
3.6 ¿Cómo se calculan en SHARE las tasas de retención?
Después de varias olas, pueden calcularse distintos tipos de ratios de retención que dependan de participaciones anteriores, pudiendo variar entre países debido a diferencias en la composición de la muestra. En SHARE podemos diferenciar los siguientes conceptos:
Retención individual excluyendo recuperación.
Retención individual incluyendo la recuperación de encuestados actuales.
Retención individual incluyendo la recuperación de encuestados actuales y parejas nuevas/perdidas.
Más información detallada sobre la participación de los encuestados en la primera entrevista y el desarrollolongitudinal de la encuesta incluyendo tasas de respuesta y retención puede encontrarse en este Documento técnico.
3.7 ¿Cómo son afrontados problemas de deserción?
Los problemas de deserción consisten en que los encuestados dejen de realizar las encuestas con el tiempo. Las razones pueden ser múltiples. Para una muestra longitudinal que fuera escogida de forma aleatoria al principio del recopilamiento de datos, la deserción de la muestra no supone ningún desafío si esta ocurre de forma aleatoria (que no es el caso en la realidad). Además de renovar la muestra en algunos países (que depende también del presupuesto) la estrategia de SHARE para afrontar problemas de deserción es dedicar un esfuerzo especial en reentrevistar a los encuestados que hayan participado en previas olas y proporcionar ponderaciones calibradas. Bajo algunas circunstancias, estas ponderaciones pueden ayudar a reducir el sesgo selectivo potencial generado por la deserción de la muestra.
3.8 ¿Cómo se documenta la mortalidad en SHARE?
SHARE clasifica el estado de los encuestados como “vivo”, “muerto” o “desconocido”. Tenga en cuenta que debido a la falta de registro de defunción en la mayoría de países europeos no podemos determinar de forma segura el estado de aquellos que no respondan. Para más información puede visitar el siguiente Documento técnico (inglés).
3.9 ¿Hay alguna base de datos que conecte los datos administrativos con los datos SHARE?
Los datos de una encuesta pueden abarcar un amplio rango de temas. Sin embargo, una encuesta no puede cubrir todos los temas de interés y la información proporcionada por los encuestados podría ser incompleta o inexacta. Los datos administrativos son más precisos pero suelen ser limitados en ciertos ámbitos. Conectar los datos de la encuesta con los administrativos es la mejor forma de combinar los dos. Bajo el consentimiento de los encuestados, los datos administrativos del Fondo de Pensiones Alemán están conectados a los resultados de la encuesta sobre la muestra alemana de SHARE (SHARE-RV). De la misma forma, otros proyectos de conexión se han realizado en otros países de SHARE: Austria, Bélgica, Estonia, Dinamarca, Finlandia, la provincia de Girona en España, Luxemburgo y Holanda. Para más información sobre este proyecto, vaya a la pregunta 6.3.
3.10 ¿Es SHARE éticamente aprobado?
El estudio de SHARE es sometido a continuos análisis éticos. Desde la primera a la cuarta ola, SHARE fue revisado y aprobado por el Comité de Ética de la Universidad de Mannheim. Desde la ola 4 en adelante, el proyecto fue revisado y aprobado por el Consejo de Ética de la Sociedad Max Planck. Además, las aplicaciones nacionales de SHARE son revisadas y aprobadas por los respectivos comités éticos o juntas institucionales de revisión cuando sea requerido. Las numerosas revisiones cubren todos los aspectos del análisis de SHARE, incluyendo sub-proyectos y confirmando que el proyecto cumple con las leyes relevantes y que el proyecto y su procedimiento concuerdan con los modelos éticos internacionales. Puede visitar el siguiente enlace para ver un resumen de la autorización ética (inglés)
4. ESTRUCTURA Y CONTENIDO
4.1 Cúal es la diferencia entre la entrevista SHARE normal y la entrevista SHARELIFE?
SHARE es un estudio de panel en el que en cada ola se pregunta sobre una serie de temas centrales. Para complementar la información de la vida de los encuestados de 50 en adelante que se recoge en las entrevistas de panel normales, se lleva a cabo en la ola 3 y 7 una entrevista especial que cubre los eventos de la vida anterior del encuestado: Esta es la entrevista SHARELIFE. Mientras que la ola 3 solo contenía puntos de la vida en retrospectiva, la ola 2 contiene una combinación. Todo encuestado que no participó en SHARELIFE en la ola 3 completó una entrevista de eventos de vida (el 81.8% de encuestados). Los que ya habían participado en SHARELIFE en la ola 3 completaron una entrevista de panel normal en la ola 7 (18.2% de ellos).
La variable mn103_ en el módulo de la variable técnica contiene información del tipo de entrevista (entevista de enventos de vida sí/no).
4.2 ¿Qué información contiene el cuestionario de SHARE normal?
La entrevista SHARE consiste en varios bloques o módulos temáticos. Anterior a la entrevista principal, un miembro de la unidad familiar completa la información general (cv_r_module) en nombre de la familia. Este cuestionario principal se basa en varios módulos CAPI diferentes. Para recoger temas actuales y a causa de restricciones y limitaciones de tiempo, no todos los módulos formó parte de todas las olas.
4.3 ¿Qué contiene SHARELIFE?
EL cuestionario SHARELIFE tiene un objetivo diferente al de las olas normales. Contiene todas las áreas importantes de la historia de la vida de los encuestados, desde la calidad de vida de la infancia, parejas e hijos, historia financiera y de empleo hasta preguntas detalladas sobre salud y cuidado de la salud.
4.4 ¿Qué es easySHARE?
EasySHARE es una abse de datos HRS-adaptada simplificada para la formación de estudiantes y para investigadores con poca experiencia en análisis cuantitativo de datos de estudios complejos. EasySHARE guardaen una única base de datos información de todos los encuestados y de todas las olas de colección de datos liberadas actualmente. La dificultad del conjunto de variables contenidas en easySHARE se reduce considerablemente. esaySHARE está guardado como base de datos de panel en formato largo. Además de los datos y de la Guía de Publicación, la descarga de los ficheros zip incluye el programa Stata que se usó para extraer easySHARE de la base de datos SHARE original. Esto permite a los usuarios realizar un seguimiento de cómo se extrajo y modificó cada variable y facilita añadir y cambiar información. También se puede usar como ejemplo de cómo se crea una base de datos para el análisis. Para más información por favor pinche aquí.
4.5 ¿SHARE incluye información sobre raza/etnia?
No, SHARE no incluye información sobre raza o etnia. Sin embargo contiene el país de nacimiento (dn004_+dn005c) y la ciudadanía (dn007_+dn008c) de los encuestados, ambos disponibles en módulo demográfico. A partir de la ola 5 SHARE también incluye en país de nacimiento de los padres del encuestado (dn504c + dn505c). La introducción de esta última variable permite identificar migrantes de segunda generación. Ciudadanía y país de nacimiento están codificados según ISO 3166-1 (numerico-3).
4.6 ¿Qué tipo de información ofrece en el módulo de observación del entrevistador?
El entrevistador responde este módulo justo al terminar la entrevista. Contiene información sobre la experiencia durante, lo que es importante a la hora de entender las circunstancias bajo las cuales se llevó a cabo.
4.7 ¿Qué es un cuestionario “drop-off”?
La entrevista finaliza con un cuestionario que se completa a lápiz en papel. Este cuestionario incluye preguntas adicionales como por ejemplo salud física y mental, atención médica y relaciones sociales. En la ola1, 2 y 4, los cuestionarios “drop-off” se llevaron a cabo en todos los países. Parte de su contenido es específico a cada país. Especialmente el cuestionario “drop-off” de la ola 4 contiene preguntas específicas a cada país a parte de la parte general de salud y atención médica. Los cuestionarios “drop-off” solo en algunos países incluyen unicamente preguntas específicas del país a partir de la ola 5.
4.8 ¿Qué son “vignettes”?
Para las vignettes se tomaron muestras extra en ocho países en la ola 1 (BE, DE, ES, FR, GR, IT, NL, SE) y en 11 países en la ola 2 (BE, CZ, DK, DE, ES, FR, GR, IT, NL, PL, SE) para obtener un cuestionario especial con preguntas de viñetas de referencia. Estas se supone que mejoran la comparabilidad entre naciones. Dos tipos se asignaron de forma aleatoria a los encuestados. Se diferencian en cuanto al orden de las preguntas y al género de las personas descritas en los enunciados. La variable “type” contiene información sobre el tipo de “vignette”. Los nombres de las variables muestran qué preguntas corresponden al otro tipo.
4.9 ¿Qué tipo de mediciones físicas se incluyen en SHARE?
Mediciones físicas y biomarcadores son parte de SHARE desde que hay aportan valor científico. Las preguntas estándar sobre la salud suelen estar sujetas a la evaluación o percepción subjetiva del encuestado. Mediciones objetivas son de ayuda para (1) validar los informes de autoevaluación de los encuestados, (2) entender las complejas relaciones entre el estatus social y la salud y sus antecedentes psicológicos and (3) para identificar patologías previas. SHARE combina informes de autoevaluación de la salud con cuatro mediciones de la condición física: fuerza de agarre (GS), velocidad de caminar (WS), flujo máximo (PF), evaluación de resistencia muscular (CS). Además, en la ola 6, se recogieron muestras de sangre seca (DBS) en 12 países: Bélgica, Dinamarca, Estonia, Francia (solo una submuestra), Alemania, Grecia; Israel, Italia, Eslovenia, España. Suiza y Suecia. Los datos DBS aún no están disponibles. Por favor subscríbase en la newsletter para ser informado tan pronto estén disponibles.
4.10 ¿Qué tipo de mediciones físicas se incluyen en SHARE?
SHARE pide que los entrevistadores confirmen a través un representante el fallecimiento de los encuestados. En caso de fallecimiento, los entrevistadores intentan llevar a cabo una entrevista de final de vida con un representante. Este puede ser un miembro de la familia, vecino o cualquier persona del círculo social más cercano del fallecido. La entrevista de final de vida contiene principalmente información de sus condiciones de vida el año anterior a fallecer así como las circunstancias de la muerte como el momento y la causa. LAs variables se guardan en xt-module a partir de la ola 2. Aparte de la entrevista de final de vida, el gv_allwaves_cv_r contiene las variables deadoralive, deceased_year, deceased_month and deceased_age.
5. TRATAMIENTO DE DATOS
5.1 ¿Cómo puedo unir los datos?
Para unir diferentes módulos y/o olas de datos de SHARE a nivel individual, mergeid es el identificador personal clave. Mergeid no varía entre olas. Si los datos van a unirse a nivel de unidad familiar, uno de las variables hhid’w’ (donde ‘w’ se refiere a la ola correspondiente) debe usarse como el identificador clave.
5.2 ¿Por qué el número de coverscreen (información demográfica general) no coincide con el de otros módulos?
Coverscreen incluye a todos los miembros de una unidad familiar - también los inelegibles y los que no respondan, así como las entrevistas de salida realizadas por representantes de aquellos encuestados fallecidos entre olas. El número de caso en otros módulos CAPI normales es inferior porque estos solo incluyen personas entrevistadas. Los miembros de una unidad familiar no entrevistados pueden ser identificados por la variable interview en el módulo cv_r. Este toma el valor 0 para aquellos que no hayan realizado la entrevista.
5.3 ¿Cómo pueden identificarse las parejas?
En SHARE, las parejas pueden ser identificadas con mergeidp’w’ (donde ‘w’ se refiere a la ola correspondiente), que indica el mergeid de la pareja del encuestado. Cada pareja tiene un coupleid (identidad de la pareja) indicado por la variable coupleid’w’. Esta identidad se genera usando el mergeid de ambos y es, por lo tanto, única para cada pareja, así como fija para cada ola si la pareja se mantiene.
5.4 ¿Por qué algunas variables como educación o altura contienen tantos valores en blanco?
La razón de ello es que las variables constantes en el tiempo solo se preguntan en la entrevista de referencia. Esta entrevista es la primera entrevista SHARE de cada encuestado. La muestra de SHARE se renueva de vez en cuando en algunos países, que es por lo que la entrevista de referencia no es necesaria.
La altura es solo un ejemplo de variable constante. Si los usuarios quieren usar estas variables en olas posteriores a la primera vez en que la entrevista de referencia tuvo lugar, la información tiene que ser transferida uniendo primero las olas y después asignando la información a olas posteriores. Además, también algunas preguntas hechas a la muestra longitudinal sobre cambios desde la última entrevista, como el estado civil. Esto lleva también a un gran número de valores perdidos en la variable correspondiente.
5.5 ¿Qué son los unfolding brackets?
Cuando un encuestado desconoce (DK) o se niega (RF) a contestar a una pregunta sobre una cantidad de dinero, normalmente comienza una secuencia de preguntas entre corchetes. El objetivo de esto es llegar a un rango en que está localizado, por ejemplo, el salario del entrevistado.
Hay tres puntos de entrada, siendo el primero elegido aleatoriamente. La presentación pública incluye los valores específicos de un país (en Euros) y la categoría final del entrevistado. Cuando se da un DK o RF durante esta secuencia de preguntas, el valor categórico final asignado es DK o RF. El nombre de las variables de esta secuencia incluye ‘ub’ después del identificador del módulo correspondiente y el número de la pregunta (ver pregunta 5.6)
5.6 ¿Cuál es el formato general para nombrar las variables?
El nombre de las variables coincide para todas las olas. Los nombres de las variables de los datos CAPI utilizan el siguiente formato: mmXXXyyy_L. “Mm” es el identificador del módulo, como por ejemplo DN si se trata del demográfico. “XXX” se refiere al número de la pregunta, por ejemplo “001”, y “yyy” son los dígitos opcionales para las variables categóricas (indicadas por la letra “d”), la conversión al euro se indica con “e” y la secuencia de preguntas entre corchetes con “ub”. “L” son los dígitos opcionales para categoría o indicadores de bucle.
5.7 ¿Para qué sirve el ado-file sharetom?
El ado-file sharetom es un programa que recodifica los valores perdidos y los identifica de forma aproximada. Para los usuarios que quieran utilizar este programa, recomendamos ejecutarlo inmediatamente después de abrir el archivo de datos o después de unir los módulos necesarios. Tenga en cuenta que sharetom se actualiza de vez en cuando. La versión actual es sharetom5.
5.8 ¿Es posible realizar un análisis longitudinal de los hijos de los encuestados?
Para análisis longitudinales sobre los hijos, los usuarios no pueden contar con el orden de los hijos en el módulo CH. Es necesario emparejarlos por género y fecha de nacimiento (para corregir la unificación de datos). Hay dos razones para esto: primero, los encuestados deben registrar a sus hijos en el orden correspondiente, pero no necesariamente lo hacen; segundo, las parejas pueden variar y los encuestados pueden no siempre registrar los hijos de ambas parejas. Además, nunca puedes excluir los errores reportados.
5.9 ¿Pueden estar conectados los hijos del módulo CH con información de ayudas sociales (SP) y transferencias financieras (FT)?
En la ola 4, los hijos nombrados por los encuestados en el módulo CH no pueden unirse directamente a los módulos SP y FT. La razón es un cambio en la lista con relaciones que incluyen a todas las personas del entorno social del entrevistado. La información de las personas recibiendo o proporcionando ayuda social o transferencias financieras de o hacia los encuestados se basa en esta lista. A diferencia de las olas 1 y 2 en las que la lista podía incluir hasta 9 hijos, la lista de relaciones en la ola 4 podía incluir hasta 7 miembros de su entorno social y solo una opción de “otro hijo”. Solo aquellos hijos nombrados por el encuestado como miembros de su entorno social son explícitamente listados para la entrevista. Por lo tanto, no es posible especificar a los hijos para preguntas sobre ayudas sociales o transferencias financieras si no han sido elegidos como miembros del entorno social por cualquier razón.
5.10 ¿Por qué las variables sobre si los padres naturales están aún vivos (dn026_1 y dn026_2) contiene tantos valores omitidos en la ola 4?
Las preguntas DN026_1 and DN026_2 contienen la información sobre si los padres naturales del encuestado siguen vivos (dn026_1 para la madre del encuestado y dn026_2 para el padre del encuestado). El trayecto de estas trata con la información de olas anteriores de encuestados que ya. participaron e información del módulo de la red social. Parecido a otras variables en SHARE, la cantidad de valores omitidos se puede reducir al combinar la ola 4 con el resto de olas. Basándose en el supuesto de que las personas pertenecientes a la red social del encuestado siguen aún vivas, ña proporción de los valores se puede reducir aún más usando las variables sn005*. Desgraciadamente la trayectoria para DN026_ y DN026_2 no funcionó correctamente para todos los encuestados en el cuestionario de la ola 4. No se preguntó a todos los encuestados que debieron ser preguntados, por lo que hay un gran numero de valores omitidos
6. VARIABLES GENERADAS
6.1 ¿Cuál es el objetivo de las variables generadas?
Para asegurar un acceso fácil y rápido a la información entre países y para trabajar de forma cómoda con los datos, es necesario que ciertas variables sean facilitadas por los usuarios SHARE, especialmente aquellos que permiten una comparación válida entre los países, como el ISCED (Clasificación Internacional Normalizada de la Educación). Además de las variables internacionales internacionalizadas, hay más variables generadas que facilitan o aumentan el trabajo con datos SHARE.
6.2 ¿Por qué es útil la información general (coverscreen) de todas las olas?
Este módulo consiste en un conjunto de datos con información unificada y enriquecida ola tras ola. De una manera directa, gv_allwaves_cv_r permite supervisar la composición de una unidad familiar, cambios en el estado civil (¿tiene el encuestado una pareja o no?; ¿está vivo o ha fallecido?; etc), y el tipo de entrevistas realizadas.
6.3 ¿Pueden estar conectadas la base de datos de SHARE con datos administrativos?
Los proyectos para relacionar la base de datos SHARE a datos administrativos se han implantado en varios países de SHARE. En Alemania, bajo el consentimiento de los encuestados, la información administrativa del Fondo de Pensiones alemán puede enlazarse a los datos de la encuesta de la submuestra alemana de SHARE. Desde la ola 3, se pregunta a todos los entrevistados de la submuestra alemana por su consentimiento para enlazar los datos de su encuesta con los datos del Fondo de Pensiones alemán. Esta base de datos longitudinal incluye información muy detallada de la vida laboral de los encuestados. El módulo gv_linkage proporciona la primera información sobre quien dio consentimiento para enlazar sus respuestas con el fondo de pensiones. Para conseguir acceso a la información administrativa, los investigadores deben presentar un documento adicional, directamente al centro de datos del Fondo de Pensiones alemán.
6.4 ¿Cuál es el contenido de gv_exrates?
Este módulo contiene las monedas (también aquellas anteriores al Euro) y los tipos de cambio para los países fuera de la Zona Euro. Además, recoge también el tipo de cambio nominal, así como el tipo de cambio que ajusta la paridad de poder adquisitivo (ppp ajustado).
6.5 ¿Qué es el Panel de Episodios Laborales (JEP)?
El JEP es un conjunto de datos generado que reordena la información recogida entre las olas 1 y 3 de SHARE para crear un “long panel” listo para su utilización. Este contiene el estado laboral de cada entrevistado en SHARELIFE a lo largo de su vida. Una descripción detallada de la metodología y las suposiciones bajo la construcción de este conjunto de datos está disponible en el papel de trabajo SHARE 11-2013: “Working life histories from SHARELIFE: a retrospective panel”, por Agar Brugiavini, Danilo Cavapozzi, Giacomo Pasini y Elisabetta Trevisan. Cuando publique con los datos de panel de los episodios laborales de SHARE, por favor utilice una renuncia adicional como se describe en el documento PDF correspondiente que se encuentra disponible al descargar los datos.
6.6 ¿Qué variables generadas sobre la salud se proporcionan?
El módulo gv_health contiene un amplio rango de variables sobre la salud y de índices relacionados con la salud indicando el estado físico y mental del entrevistado. La mayoría de estas variables es comparable al Estudio Estadounidense sobre Salud y Jubilación (HRS). Las variables del módulo de salud física son, por ejemplo, la versión estadounidense de percepción propia del estado de salud (sphus), el índice de masa corporal (bmi), el número de enfermedades crónicas (chronic), y el índice de movilidad (mobility) y las limitaciones en las actividades prácticas de la vida diaria (iadl). Las variables de la salud mental son, por ejemplo, la escala de depresión EURO-D (eurod), la medida de orientación hasta la fecha (orienti) y la puntuación matemática (numeracy).
6.7 ¿Cómo se pide el nivel educativo en SHARE?
La educación es una de las variables más diferentes internacionalmente. Por ello, se necesita una codificación estándar para comparaciones entre países. El módulo gv_isced contiene la Clasificación Estándar de la Educación de 1997 (ISCED-97). No solo informa del nivel educativo de los entrevistados sino también el de sus hijos y cónyuges. En las olas 1 y 2, se preguntaba sobre el nivel de educación de hasta cuatro hijos. La ola 4 contiene los valores de ISCED-97 para todos los hijos. En 2011, los países miembros de la UNESCO modificaron ISCED. Desde su última modificación en 1997, tiene en cuenta cambios significativos en el sistema educativo en todo el mundo. Desde la ola 5 en adelante, las dos versiones de ISCED son proporcionadas en la base de datos de SHARE. Además, el nivel educativo de los padres de los encuestados se incluyen en las olas 6 y 7.
6.8 ¿Qué información contiene el módulo gv_isco?
A los encuestados se les pregunta sobre su ocupación, la ocupación de su pareja en el momento de la entrevista y la ocupación de sus padres. Para la primera ola, esta información está codificada basándose en el Estándar Internacional de Clasificación de la Ocupación (ISCO-88) ofrecido por la Organización Internacional del Trabajo (ILO). Para clasificar las diferentes industrias, el módulo gv_isco contiene también una versión de la Clasificación Estadística de las Actividades Económicas en la Comunidad Europea (NACE versión 4 rev.1 1993), que está ligeramente modificada.
6.9 ¿Qué clase de información geográfica puede encontrarse en el módulo gv_housing?
SHARE facilita la “Nomenclatura de Unidades Territoriales para la Estadística” (NUTS), que consiste en un sistema de clasificación jerárquica para sumergirse en el territorio económico de la Unión Europea. Se utiliza para indicar en que territorio se encuentran las unidades familiares de SHARE en el momento de tomar la muestra y hay distintos niveles:
NUTS 1: regiones socioeconómicas principales.
NUTS 2: regiones básicas para aplicar las políticas regionales.
NUTS 3: regiones pequeñas para diagnósticos específicos.
Debido a razones de legislación de privacidad, no todos estos niveles están disponibles en todos los países. Por ejemplo, en Alemania solo existe NUTS 1.
6.10 ¿Cómo se recogen las relaciones sociales en SHARE?
El módulo CAPI de relaciones sociales (SN) se introdujo en la cuarta ola de SHARE como innovación, permitiendo medir el entorno social personal. El módulo fue parte también de la ola 6 y se basa en una aproximación que va más allá del método de medir las relaciones sociales basándose solo en las variables socio-demográficas. El módulo SN contiene una descripción detallada de las relaciones sociales de los encuestados. Cada uno puede nombrar un máximo de 7 personas de confianza. El módulo recoge las relaciones con cada miembro y se obtiene la siguiente información sobre cada uno: género, proximidad residencial al encuestado, frecuencia de contacto y nivel de cercanía emocional. La información sobre el módulo SN puede relacionarse a la de apoyo social (SP) y a la de transferencias financieras (FT).
Las variables generadas en el módulo “gv_networks” recogen variables que resumen la información sobre los diferentes atributos de una relación. En la sexta ola, las variables además resumen el panel de información y proporcionan una información completa de cada miembro del entorno social.
6. 11 ¿Cómo se miden las carencias?
Este módulo está disponible en la quinta ola y contiene tres variables relacionadas con carencias materiales y sociales: depmac, depsoc y depsev. La primera es una medida agregada de condiciones materiales para los individuos europeos más mayores, utilizando un conjunto de once elementos referidos a dos amplios ámbitos: el fracaso en poder permitirse necesidades básicas y las dificultades financieras. Depsoc es un índice que mide carencias sociales basándose en quince elementos. Depsev es un indicador bidimensional que identifica niveles altos de carenciade cada índice de privación. Aquellos individuos que se localicen más allá de los límites de privación debido a ciertas medidas, son clasificados como “severamente privados”.
6.12 ¿Tiene SHARE una medida para los recursos de la Seguridad Social?
Desde la emisión de SHARE 5.0.0, la cuarta ola incluye un nuevo módulo que contiene dos medidas del patrimonio acumulado de la Seguridad Social individual (SSW). Las dos variables son SSW-nw y SSW_gw. La primera se basa en el salario neto de los individuos durante su vida laboral. El segundo se basa en una extrapolación aproximada de los salarios, teniendo en cuenta además la pensión mínima que pueda recibir el individuo si está en condiciones de ello. Teniendo en cuenta que no se necesitaba información de JEP para calcular el SSW de los jubilados, las dos variables son iguales para este grupo.
6.13 ¿Cuándo será necesaria la variable gv_grossnet?
En la primera ola, las variables relativas a los ingresos se recogían antes de contabilizar los impuestos y las contribuciones a los seguros sociales, mientras que en las siguientes olas estas variables se han recogido después de impuestos y contribuciones sociales para obtener información sobre el sueldo neto. Para poder comparar las medidas relativas a los ingresos entre diferentes olas y facilitar el análisis longitudinal, el módulo gv_gross_net contiene medidas de ingresos netos desde el sueldo bruto reportado de la ola 1. Para realizar esta tarea, se utiliza el instrumento EUROMOD, un modelo de microsimulación europeo que relaciona impuestos y beneficios.
6.14 ¿Qué información contiene gv_children?
La información sobre los hijos de los encuestados se recopila en varias partes del cuestionario. Las variables del módulo gv_children se generaron con la intención de hacer más fácil el acceso a la información para los usuarios. El módulo combina información de los módulos CAPI CH, SN, SP y FT de la ola 6. Tenga en cuenta que las variables de gv_children consisten en información agregada de la ola 6, pero no de olas anteriores.
6.15 ¿Qué variables generadas se recogen dentro de gv_dbs?
Además de las variables CAPI incluídas en el módulo BS, algunas variables generadas ya se proporcionan en gv_dbs. La más importante es dbs_values_exp (disponibilidad esperada para resultados de laboratorio). Los resultados estarán disponibles solo si: (a) existe consentimiento escrito del encuestado, (b) la muestra DBS es enlazable a la encuesta CAPI a través del número de su código de barras, o (c) el papel de filtro DBS contiene suficiente material sanguíneo como para realizar, al menos, un análisis. En caso de cumplir estas tres condiciones, dbs_values:exp=1. Otras variables dentro de gv_dbs son: spots_nr (número de manchas de sangre recogidas, con valores entre 0 y 5), y spots_co (número de manchas de sangre rellenando el círculo pre-impreso). Este último indica cuántas manchas de sangre contienen la cantidad de sangre que cubra el tamaño del círculo pre-impreso (1cm de diámetro) en la tarjeta de recolección de sangre.
6.16 ¿Qué contiene gv_big5?
En la séptima ola, se introdujeron por primera vez los 10 elementos del modelo Big-Five (BFI-10), un modelo establecido de personalidad que mide las “cinco grandes” dimensiones de personalidad con dos clasificaciones cada una. Presentado por Rammstedt y John (2007) el BFI-10 es una medida ultra-corta de personalidad adecuadas especialmente para encuestas multitemáticas en las que están limitados el tiempo de evaluación y el espacio de cuestionario. Para más información sobre las medidas de los “Cinco Grandes”, por favor vea el capítulo correspondiente en el Libro de Resultados de la ola 7.
7-WEIGHTS
7.1 Hay muchos estudios de SHARE en los que no se usan datos ponderados. ¿Hay una estrategia general sobre este tema?
No es fácil dar una estrategia general a esta cuestión. En referencia al reciente estudio de Solon, Haider and Woolldridge (2013). Los autores distinguen entre dos tipos investigación empírica: (i) investigación centrada en la estimación de estadísticas de las poblaciones, and (ii) investigación dirigida a la estimación de efectos causales (por ejemplo, para conseguir estimadores más precisos al corregir la heterosquedasticidad o para conseguir estimadores más consitentes al corregir el muestreo endógeno). Por este motivo, la ponderación se hace para que el análisis de la muestra sea representativo de la población. La elección de usar estadísticas de muestras ponderadas es intuitivo sin ser controvertido: las estadísticas demográficas se pueden estimar de forma consistente a partir de muestras estadísticas ponderadas. En cuanto a esto último, la cuestión de si se debe ponderar o no y de cómo hacerlo está matizada. Los investigadores tienen que tener clara la razón por la que usar estimaciones ponderadas, pensar detenidamente si es una buena razón y comprobar los diagnósticos apropiados. En caso de que se vaya a ponderar, suele ser útil dar los estimadores ponderados y los que no y discutir que implican sus diferencias a la hora de interpretar los resultados. Se aconseja igualmente usar estimadores con errores estándar robustos.
7.2 ¿Qué ponderaciones se deben usar para análisis transversales y cuáles para análisis longitudinales?
SHARE ofrece ponderaciones transversales y longitudinales calibradas. Para análisis transversales, la ponderación calibrada que se debe usar depende de la unidad de muestra básica de análisis. Por ejemplo, en la ola 4, si la unidad de muestra básica es es individual se usa es la variable cciw_w4 y si la unidad de muestra básica es una unidad familiar se usa cchw_w.
Para análisis longitudinal, la ponderación calibrada que se debe usar depende tanto de la combinación de ola de interes (p.e. olas usadas para formar un panel) al igual que la unidad de muestra básica. Por ejemplo para un panel equilibrado (combinación de olas 1-2-3-4-.5-6-7), se usa la variable cliw_a en caso de que la unidad de muestra básica sea individual y clhw_a si la unidad de muestra básica es una unidad familiar
Para análisis longitudinales basados en combinaciones de olas diferentes, los usuarios deben computar sus propias ponderaciones calibradas. Para ayudar a los usuarios en esta tarea, ofrecemos un do-file de Stata llamado “cweight.ado” que muestra el proceso de calibración de Deville and Särdan (1992), así como do-files de Stata que muestran paso a paso como computar ponderaciones longitudinales calibradas a nivel individual y de unidad familiar. Para más información pinche aquí.
7.3 En la sección 8.7 de Innovación y Metodología de la Ola 4 se menciona que están disponibles para los usuarios de SHARE un do-file ponderado y el comando en Stata cweight.ado ¿Dónde puedo encontrarlos?
El archivo do-file cweight.ado al igual que el resto de archivos que se proporcionan para general ponderaciones longitudinales calibradas se pueden descargar desde la página web de la página web normal de SHARE “Generate Calibrated Weights Using Stata 1.0.0”). Se debe tener en cuenta que actualmente estamos trabajando en la actualización de estos archivos y que estarán disponibles lo antes posibles.
7.4 ¿Cuál es la diferencia entre las ponderaciones de las diferentes Olas?
El diseño de la de ponderación de la muestra puede diferir entre olas a causa de las diferencias entre países en los diseños del muestreo. Ponderaciones longitudinales y transversales calibradas están en cambio computadas en todas las olas siguiendo el proceso de Deville y Särndal (1992) . La otra gran diferencia con respecto a olas anteriores son que (i) ya no se distingue entre variantes alternativas de la muestra SHARE (p.e. La muestra principal, muestra viñeta y ambas combinadas); (ii) ya no se ofrecen ponderaciones calibradas transversales de las parejas que no responden por un cambio sustancial en el proceso de imputación en la ola 4; (iii) ya no se ofrece tampoco ponderaciones longitudinales para todas las posibles combinaciones de olas creando un panel.
7.5 ¿Se pueden quitar observaciones de la muestra que contengan ponderaciones omitidas?
Datos omitidos en el diseño del muestreo y en las ponderaciones calibradas se puede deber a (i) edad ineligible (p.e. Encuestado menor de 50 añis), (ii) falta de información en el muestreo, (iii) falta de información en el conjunto de variables calibradas (edad, género, código regional NUTS1), (iv) encuestados que no pertenezcan a la muestra balanceada seleccionada (solo para ponderaciones longitudinales calibradas). Observaciones con ponderaciones omitidas no son un problema si se quieren hacer inferencias sobre la población mayor de 50 años. Como hay pocas observaciones con ponderaciones omitidas por (i) y (ii), estas observaciones en general se pueden quitar para el análisis sustancial de los datos SHARE. Observaciones con ponderaciones longitudinales omitidas a causa de (iv) pueden causar problemas si el proceso de generar observaciones omitidas no es aleatorio (basado en el conjunto de variables condicionales). Se debe tener en cuenta que para compensar el desgaste, los usuarios deberían usar un conjunto mayor de variables usando la información disponible de la ola inicial. También se pueden usar métodos alternativos como ponderaciones basadas en la puntuación de propensión y en modelos de selección de muestra para imponer una hipótesis más débil sobre el mecanismo de los datos omitidos asociado con el desgaste.
7-IMPUTATIONS
8.1 ¿Cuál es el método de imputación?
Los elementos se pueden imputar o secuencialmente a través de un método “hot-deck” o conjuntamente a través del método de especificación condicional total (FCS). Imputations “Hot-deck” se llevan a cabo de forma separada por países, mientras que imputaciones FCS se llevan a cabo por país y tipo de muestra (solteros y terceros encuestados, parejas con ambos entrevistados y todas las parejas con o sin pareja que no responde). Para cada ola y país, el método FCS se usa solo para variables monetarias que satisfacen el requerimiento de tener al menos 100 observaciones en la muestra 1 (solteros terceros encuestados) y 150 observaciones en la ola 2 ( parejas con ambos entrevistados) y muestra 3 ( todas las parejas con y sin pareja que no responde). Independientemente del modelo de imputación elegido, SHARE proporciona de cada variable cinco imputaciones múltiples de los valores omitidas.
8.2 ¿Las variables imputadas se pueden usar para el análisis longitudinal?
Sí pero puede causar varios problemas. Primero, los usuarios deben comprobar si las variables de interés se han imputado en todas las olas de interés y si la información subyacente es perfectamente comparable a través de las olas. SEgundo, los usuarios deben tener en cuenta que el modelo de imputación no incluye variables retrasadas de la ola anterior como indicadores de los valores omitidos en la ola actual. Esto implica que el modelo de imputación puede ser menos general que el modelo usado para analizar los datos longitudinales imputados (véase Meng 1994 para la discusión de este problema de incompatibilidad). Para solucionar este problema, planeamos usar en futuros datos SHARE modelos de imputación más generales.
8.3 ¿Por qué el módulo de imputación contiene tantos casos?
SHARE proporciona múltiples imputaciones de los valores omitidos para que los usuarios puedan tener en cuenta la variabilidad adicional inducida por el proceso de imputación al evaluar la precisión de los estimadores (véase Rubin 1987). El método de imputación múltiple implica que hay m>1 valores imputados para cada valor omitido. EN SHARE, el número de imputaciones es m=5. Por ello, hay 5 imputaciones independientes indizadas por la variable “implicat”. Se debe tener en cuenta que las observaciones difieren solo respecto a los valores imputados pero que son idénticas respecto a los casos completos. Los usuarios que quieran apoyarse en un único método de imputación (pese a nuestro aviso de tener en cuenta la variabilidad inducida por el proceso de imputación) pueden seleccionar solo uno de los cinco “implicats” disponibles. Ya que hay cinco sorteos independientes de la distribución estimada de los valores omitidos, no hay ninguna razón para elegir un “implicat” en vez de otro.
8.4 ¿Por qué las variables imputadas en el “Release 5.0.0” en adelante son diferentes de los anteriores?
Como se ha dicho en la documentación, hay diferencias en los datos brutos así como innovaciones en el proceso de imputación. Para esto último, hay grandes diferencias con respecto al proceso de imputación adoptado en emisiones anteriores de la ola 1 y 2: (i) la forma de tratar con el problema de las parejas que no responden, (ii) el uso de un conjunto más pequeño de variables, (iii) un número menor de indicadores y (iii)el uso de dos mediciones alternativas del ingreso total de las familias. El objetivo de estos cambios es tener un modelo de imputación más fiable pero es difícil solucionar las implicaciones de todas estas diferencias en el análisis sustancial de los datos SHARE.
8.5 ¿Por qué hay dos variables para el ingreso de las familias?
Desde la Ola 2, SHARE recoge datos de de dos definiciones diferentes de los ingresos totales de las familias: “thinc” es la suma del ingreso individual imputado de todos los miembros de la unidad familiar, mientras que “thinc2” es la medición del ingreso total de las familias recogida en la pregunta HH017.
En nuestra opinión, la elección entre estas dos mediciones alternativas no es fácil y por ello dejamos a nuestros usuarios decidir cuál de las dos mediciones es más adecuada para sus preguntas de investigación. Además, nuestro modelo de imputación usa ambas mediciones. Respecto a eso, recomendamos encarecidamente a los usuarios llevar a cabo análisis sensitivos de las dos mediciones disponibles. Esto puede ayudar a entender cuál de las dos mediciones es más adecuada sobre la base científica.
8.6 ¿Están convertidas a Euro las cantidades monetarias de la base de datos?
Sí, todas las variables monetarias están expresadas en euros anualmente. Esto implica que cuando son ajustadas a la paridad de poder adquisitivo (PPP) en los países fuera de la zona Euro, las cantidades deben ser primero convertidas a la moneda doméstica utilizando la variable exrate y después en cantidades ajustadas de paridad del poder adquisitivo, dividiendo la moneda doméstica entre el tipo ajustado de PPP.
8.7 ¿Qué significan las abreviaciones en la variable htype?
1 S= hogar unipersonal
1 CNRP = hogar con una pareja y una pareja que no responde
1 C2R = hogar con una pareja en la que ambos responden
1 CNRP + 1S = hogar con una pareja, en la que uno no responde + una persona soltera
Multi S = hogar constituido por varios solteros
1 C2R + 1S = hogar con una pareja en la que ambos responden + una persona soltera
Multi C2R = hogar con varias parejas que responden
Multi CNRP = hogar con varias parejas en la que uno de la pareja no responde